Linux 内存管理(6):进程地址空间的管理
Linux 内存管理(6): 进程地址空间的管理
所谓的“进程地址空间(address space),就是进程可以使用的全部的线性地址。
在内核中的函数以简单的方式获得内存,可以直接以页框为单位获取一段内存,也可以用 kmalloc或者vmalloc以字节为单位获取连续的或不连续的内存。由于内核是操作系统中最 高优先级的部分,所以被内存的请求会被马上响应并且真的分配出来。另外由于内核信任 自己,所以内核函数不必插入对编程错误的任何保护措施。
但给用户态的进程分配内存时情况很不相同。
首先,进程对动态内存的请求被认为是不紧迫的。当进程的可执行文件被装入时, 进程并不一定立即对所有的代码进行访问,当进程调用malloc()时,其申请的内存并不 一定很快会被访问。另外,用户进程是不可信任的,内核需要随时准备捕获用户态进程所 引起的寻址错误。
所以,内核会尽量“推迟”对用户态进程的内存分配。当用户态进程请求动态内存时,并 没有真正获得页框,而仅仅获得了对一个新的线性地址区间(即所谓的VMA)的使用权, 同时这一线性地址区间就成为进程地址空间的一部分。
内存描述符
内核使用内存描述符结构体(struct mm_struct)表示进程的地址空间,该结构包含了和
进程地址空间有关的全部信息,包括计数器、包含的内存区域、页全局目录、各个段的地
址等等。
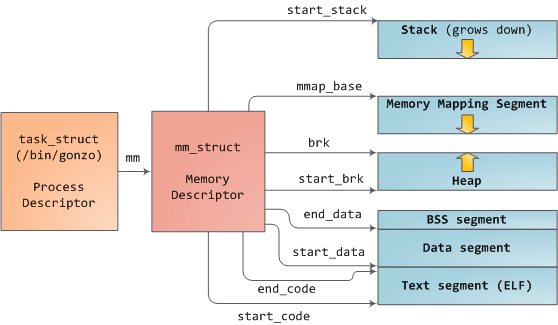
在进程的task_struct中的mm域就指向mm_struct结构,结构体中需要重点关注的字
段如下:
struct mm_struct {
...
struct vm_area_struct *mmap; /* VMA链表 */
struct rb_root mm_rb; /* VMA形成的红黑树 */
struct vm_area_struct *mmap_cache; /* 最近使用的内存区域 */
pgd_t *pgd; /* 页全局目录 */
atomic_t mm_users; /* 使用该地址空间的用户数 */
atomic_t mm_count; /* 主使用计数器 */
int map_count; /* 内存区域的个数 */
struct list_head mmlist; /* 所有mm_struct形成的链表 */
...
}
mm_users域记录正在使用改地址的进程数目。事实上使用同一个地址空间的进程就是线
程。
当mm_count为0时,表示没有任何指向该结构体的引用了,该结构体会被撤销。
mmap和mm_rb两个结构体表述的都是该地址空间中所有的“内存区域”(内存区域下一小
节讨论),只不过前者是以链表的形式存放,后者是以红黑树的形式存放。链表方便遍历
,红黑树方便搜索。
所有的mm_struct通过自身的mmlist域链接在一个双向链表中,该链表的首元素是
init_mm内存描述符,它代表init进程的地址空间。
进程fork时,子进程中的mm_struct结构体实际是通过文件kenel/fork.c中的
allocate_mm()宏从 mm cachep slab 缓存中分配的。通常每个进程都有唯一的
mm_struct,即唯一的地址空间。如果在调用clone()时设置CLONE_VM标志,那么父
进程和子进程就共享地址空间,子进程的task_struct中的mm就直接指向父进程的
mm_struct,这样的进程就是线程。
mm_struct 和内核线程
内核线程没有进程地址空间,也没有相关的内存描述符。所以内核线程的task_struct
中的 mm 域为NULL。事实上,这也正是内核线程的真实含义——没有用户上下文。
但尽管内核线程不需要使用进程地址空间,但即使访问内核内存,也需要使用一些数据,
比如页表,而这些数据一般是放在mm_struct中的。对此,Linux的方案是内核线程直接
使用上一个进程的mm_struct。
当一个内核线程被调度时,内核发现它的mm域为NULL,就会保留前一个进程的地址空间,
随后内核更新内核线程对应的task_struct中的active_mm域,使其指向前一个进程的
task_struct。
虚拟内存区域(VMA)
VMA结构
虚拟内存区域(virtual memoryAreas,VMAs)由vm_area_struct结构体描述,它描述了
指定地址空间内连续区间上的一个独立内存范围。内核将每个VMA作为一个单独的内存对象
管理,每个VMA都拥有一致的属性,比如访问权限等,相应的操作也都一致。
该结构体定义在<linux/mm_types.h>中:
struct vm_area_struct {
struct mm_struct * vm_mm; /* 关联的mm_struct. */
unsigned long vm_start; /* VMA首地址 */
unsigned long vm_end; /* VMA尾地址 */
struct vm_area_struct *vm_next, *vm_prev; /* VMA组成一个链表 */
pgprot_t vm_page_prot; /* Access permissions of this VMA. */
unsigned long vm_flags; /* 标志 */
struct rb_node vm_rb; /* 连接到红黑树 */
union {
struct {
struct list_head list;
void *parent; /* aligns with prio_tree_node parent */
struct vm_area_struct *head;
} vm_set;
struct raw_prio_tree_node prio_tree_node;
} shared;
struct list_head anon_vma_chain;
struct anon_vma *anon_vma;
const struct vm_operations_struct *vm_ops;
unsigned long vm_pgoff;
struct file * vm_file; /* 所映射的文件 (can be NULL). */
void * vm_private_data; /* 私有数据 */
};
结构体中的vm_mm指向相关的mm_struct结构体,vm_start表示VMA的首地址、
vm_end表示VMA的尾地址。vm_flags表示VMA的标志。
几个常用的标志是:
VM_READ,VM_WRITE和VM_EXEC标志了VMA中页面的读、写和执行权限。VM_SHARED指明了内存区域包含的映射是否可以在多进程间共享,如果该标志被设置 ,则成为共享映射,如果没有被设置,而仅仅只有一个进程可以使用该映射的内容, 则叫做私有映射。VM_IO标志内存区域中包含对设备I/O空间的映射。VM_SEQ_READ标志暗示应用程序对映射内容执行有序的读操作,这样内核可以有选择 地执行预读文件。VM_RAND_READ意义正相反。vm_file表示映射的文件,一个没有映射任何文件的VMA被称作是匿名的。
VMA操作
vm_area_struct中的vm_ops域指向VMA相关的操作函数表(和VFS的方式类似)。
操作函数表由vm_operations_struct表示,一个简化版(去掉NUMA相关的内容)的
vm_operations_struct如下:
struct vm_operations_struct {
void (*open)(struct vm_area_struct * area);
void (*close)(struct vm_area_struct * area);
int (*fault)(struct vm_area_struct *vma, struct vm_fault *vmf);
int (*page_mkwrite)(struct vm_area_struct *vma, struct vm_fault *vmf);
int (*access)(struct vm_area_struct *vma, unsigned long addr,
void *buf, int len, int write);
}
进程所拥有的VMA从来不重叠,并且内核尽力把新分配的VMA与紧邻的现有VMA进行合并:
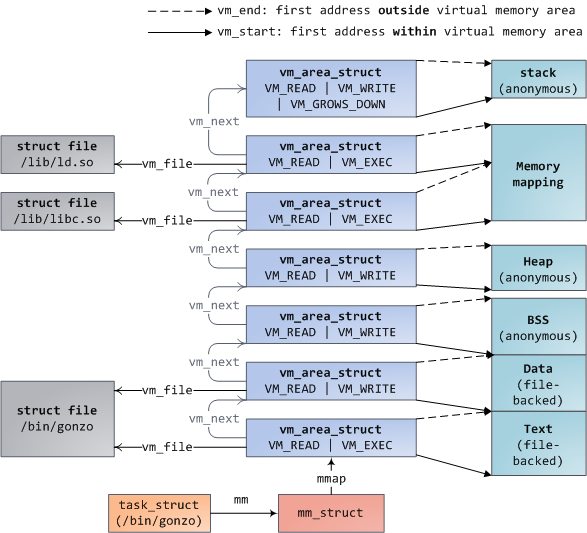
mm_struct 和 vm_area_struct 的组织
前面说到,vm_area_struct同时以链表形式和红黑树形式存在与mm_struct中 。
对于链表结构,每一个vm_area_struct都通过自身的vm_next域被连入链表,所有的区
域按照地址增长的方向排序。当我们查看/proc/pid_of_process/maps时,内核就通过
链表遍历所有的VMA并打印出来。
对于红黑树,mm_struct中的mm_rb就指向红黑树的
根节点,每个VMA通过vm_rb连接到树中。红黑树的搜索、删除和插入操作的复杂度都为
O(log(n))。
task_struct,mm_struct和vm_area_struct的组织实例如下图:
VMA的工作方式+一个例子
VMA作用在内核和进程之间。程序发出一个请求(请求一块内存或者请求映射一个文件), 内核回答说“OK“,但并没有真的找一块物理内存给程序,而只是修改或者创建VMA,让 进程以为已经得到想要的内存了。当进程真的用到了更新过或是新申请的VMA时,发现 VMA中的页没有指向一个有效的页表项(PTE),这就会引发一个页错误(page fault), 这时内核才会去去老老实实地做些事情,分配一块物理内存或者其他事情,然后修改页表 ,使VMA中的页映射到“正确”的页表项(PTE)。
一个例子。
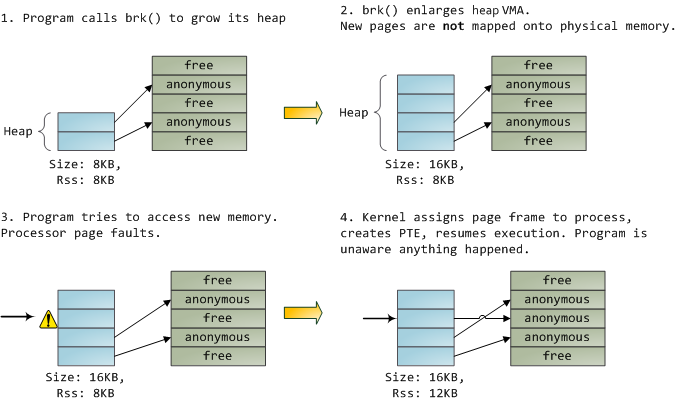
- 进程通过
brk()系统调用申请一块内存,这块内存应该在heap的VMA上。 - 内核更新VMA,系统调用返回“OK”,此时并没有物理内存页表被真的分配出来。
- 进程试图使用这块内存,引发处理器的page fault,函数
do_page_fault()被调用 。该函数通过find_vma()搜索包含了这部分地址的VMA,如果没有找到,则触发 “段错误(Segmentation Fault)”。 - 找到了对应的VMA,在对VMA做一些权限方面的检查后,内核试图通过页表找到物理内
存地址。当发现并没有一个PTE为为这个虚拟内存页服务,内核知道这部分虚拟内存从
来没有被映射过,并且这个VMA是匿名的,于是内核调用
do_anonymous_pages(),从 物理内存中分配一个页框,然后创建一个PTE来把出现fault的虚拟页map到刚分配到的 物理页框上。
对于交换出去的页框,它的PTE中”P”标志为0,代表它当前不在物理内存中,但它的地址又 不为空,事实上,它存的是交换地址,通过一个“缺页异常”,内核从硬盘上读取这部分 内容并且加载到内存中。
缺页异常
当程序访问一个页,这个页在进程的地址空间中存在,但是在没有加载到物理内存中时, 就会由硬件引发一个 trap, 这就叫做“缺页异常(Page Fault)”。操作系统一般会通过两 种方式处理缺页异常,一是使请求的页可访问,二是当请求访问的页不合法时,就终止 程序。也就是说,缺页异常由处理器的内存管理单元(memory management unit, mmu)触发 ,由操作系统的异常处理程序来处理。
缺页异常分为3种,参考 Page fault:
- Major, major page fault 发生时,需要从硬盘读取数据。
- Minor, minor page fault 发生时,所需要的内容已经在内存里了(可能是有其他 进程加载进来的),但是没有被mmu标记,所以只需要修改相关的内容指向正确的位置 就行。
- Invalid, 所请求的地址不在进程地址空间内,就触发一个invalid page fault。
缺页异常处理程序的总体方案如下图:
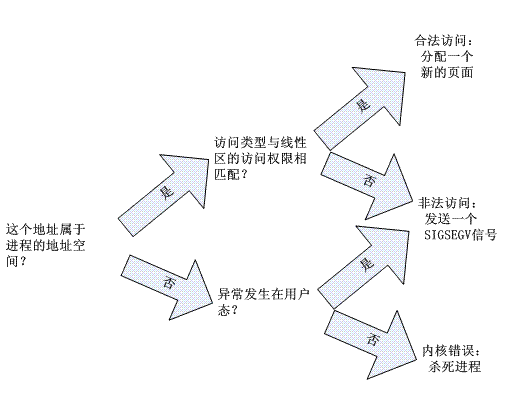
具体的处理流程大致如下:
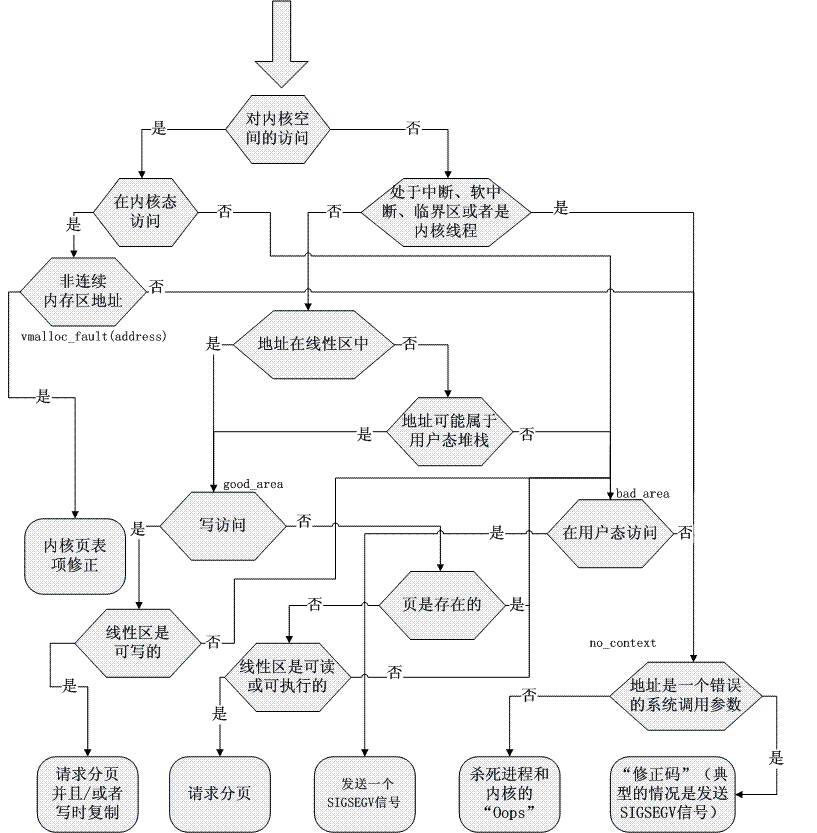
VMA的操作
find_vma()
内核通过find_vma()来找到一个给定的内存地址属于哪一个内存区域。
该文件定义在<mm/mmap.c>中:
struct vm_area_struct * find_vma(struct mm_struct *mm, unsigned long addr);
搜索通过mm_struct中的红黑树进行。它会返回第一个vm_end大于addr的VMA。
返回的结果会缓存在mm_struct的mmap_cache中。
find_vma_prev()
和find_vma()类似,只是返回的是第一个小于addr的VMA。
struct vm_area_struct * find_vma_prev(struct mm_struct *mm,
unsigned long addr,
struct vm_area_struct **pprev)
find_vma_intersection()
返回第一个和指定地址区间相交的VMA。
mmap()和do_mmap()
内核使用do_mmap()函数创建一个新的线性地址区间。事实上,如果创建的地址区间和
一个已经存在的地址区间相邻,并且它们具有相同的访问权限的话,两个区间将合并为一
个。该函数定义在<linux/mm.h>中:
unsigned long do_mmap(struct file *file, unsigned long addr,
unsigned long len, unsigned long prot,
unsigned long flag, unsigned long offset)
该函数映射由 file 指定的文件,偏移量为 offset ,长度为 len 。如果 file 为 NULL 并且 offset 也为0,则代表这次映射为匿名映射,否则叫做文件映射。
mmap和do_mmap()类似,只不过适用于用户空间。
内核栈和中断栈
在每一个进程的生命周期中,必然会通过到系统调用陷入内核。在执行系统调用陷入内核 之后,这些内核代码所使用的栈并不是原先用户空间中的栈,而是一个内核空间的栈, 称作进程的“内核栈”。
内核为每个进程分配了一个内核栈,事实上每个进程的内核栈和它的thread_info结构在
一起。
每个进程的内核栈大小既依赖体系结构,也与编译时的选项有关。历史上每个进程都有两 页大小内核栈(对于32位系统是4x2=8K,64位系统是8x2=16K大小)。
随着机器运行时间的增加,寻找两个未分配的、连续的页变得越来越困难,物理内存渐渐 变为碎片,因此给一个新进程分配虚拟内存的压力也在增大。所以后来内核多了一个编译 选项,可以选择内核栈为1页。现在,对于32位系统,默认内核栈为2页,可以选择设置 为一页。而对于64位系统,则固定为两页(8K)。
如果内核栈为2页,中断处理程序也会使用它们中断的进程的内核栈。事实上这个内核栈 会被用于所有类型的内核控制路径:异常、中断(硬件中断)、和可延迟函数(软中断和 tasklet)。
如果编译时指定定内核栈大小为1页,则: 1. 每个进程都会有一个独立的异常栈,用于
异常处理,这个栈包含在每个进程的thread_union结构中。2. 每个CPU有一个硬中断
请求栈,大小为一页,用于处理中断。3. 每个CPU都有一个软中断请求栈,大小为一页,
用于处理可延迟函数。
参考资料: