内核中双向链表的实现
内核中双向链表的实现
list_head数据结构
为了理解内核中双向链表的实现,我们先来了解一下list_head数据结构:
/* <linux/types.h> */
struct list_head {
struct list_head *next, *prev;
};
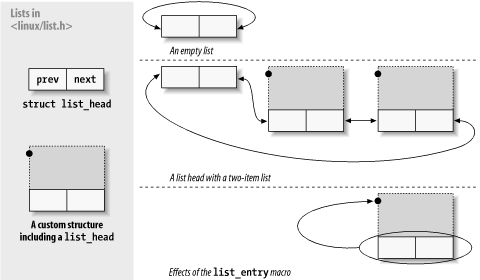
一个双向链表的元素包含一个类型为list_head的变量,list_head结构里面,next和prev分别表示通用双向列表向前和向后的指针元素。需要注意的是,入下图所示,next和prev所指向的是另一个list_head结构的地址,而非这个链表元素的地址。(要得到这个链表元素的地址,可以用list_entry()宏来得到,具体见下面)
对包含了list_head的双向列表,有以下的处理函数和宏:
-
LIST_HEAD(name)初始化一个名字叫做name的链表头
-
list_add(n, p)把n指向的元素插入p指向的元素之后
-
list_add_tail(n, p)把n指向的元素插入p指向的元素之前
-
list_del(p)删除p所指向的元素
-
list_empty(p)检查p指向的链表是否为空
-
list_entry(p, t, m)返回类型为t的数据结构的地址,其中类型t中含有list_head字段,且list_head字段的地址为p,名字为m。也就是在链表中找到一个元素,这个元素的类型为t,这个元素里面包含了类型为list_head的名称为m的属性。
-
list_for_each(p, h)对表头地址
h指定的链表进行扫描,在每次循环时,通过p返回指向链表元素的list_head结构的指针。 -
list_for_each_entry(p, h, m)与
list_for_each类似,只是返回的是链表元素的指针,也就是返回包含了地址为p且名称为m的list_head的元素的指针,而不是list_head结构本身的地址。
list_entry宏的实现
作为一个例子,我们来看看list_entry宏是怎么实现的。下面的叙述中SRC表示Linux内核源码所在的目录。
在SRC/include/linux/list.h中有如下宏:
/**
* list_entry - get the struct for this entry
* @ptr: the &struct list_head pointer.
* @type: the type of the struct this is embedded in.
* @member: the name of the list_struct within the struct.
*/
#define list_entry(ptr, type, member) \
container_of(ptr, type, member)
这个container_of宏则在SRC/drivers/staging/rtl8192e/rtllib.h中定义:
#ifndef container_of
/**
* container_of - cast a member of a structure out to the containing structure
*
* @ptr: the pointer to the member.
* @type: the type of the container struct this is embedded in.
* @member: the name of the member within the struct.
*
*/
#define container_of(ptr, type, member) ({ \
const typeof(((type *)0)->member)*__mptr = (ptr); \
(type *)((char *)__mptr - offsetof(type, member)); })
#endif
看起来很有意思,我们仔细分析一下上面的这一段宏。
-
((type *)0)把0强制转换为type类型的指针,它指向一个空的type类型
-
((type *)0)->member)*__mptr = (ptr)从上面得到的空的type类型得到类型中名称为member的一项,把ptr强制转换为member的类型的指针,赋值给变量__mptr
-
offsetof(type, member)这个宏得到的是在类型type的内存结构中,名称为member的一个属性相对预type的基地址的偏移量。这个宏的具体实现下面讲。
-
(type *)((char *)__mptr - offsetof(type, member))把之前赋值好的__mptr强制转换为char指针类型,这样可以和offsetof得到的偏移值做减法,由member的地址减去member相对于type的偏移值,得到的就是type的地址了。最后再把这个地址转换为type类型的指针。这样我们就得到了”container”的指针。
offsetof宏的实现
offsetof的宏定义在SRC/include/linux/stddef.h中:
#undef offsetof
#ifdef __compiler_offsetof
#define offsetof(TYPE,MEMBER) __compiler_offsetof(TYPE,MEMBER)
#else
#define offsetof(TYPE, MEMBER) ((size_t) &((TYPE *)0)->MEMBER)
#endif
还是同样的方法,把0强制转换为TYPE类型的指针,找到这个指针代表的TYPE元素的MEMBER属性,得到它的地址,由于是由0强制转换而来,所以这个地址就是MEMBER属性相对与TYPE结构在内存中的偏移地址。再把这个偏移地址转换为size_t类型。所谓size_t类型,也就是用sizeof函数返回值的类型,也就是用char来衡量的一个数据结构的大小的值。
事实上这里还涉及到字节对齐的问题。比如说
struct S1
{
char c;
int i;
};
S1 s1;
我们可能会想,char占1字节,int占4字节,那么sizeof(s1)等于5字节么?不是的,事实上sizeof(s1)等于8字节。这就是所谓的“字节对齐”,之所以要字节对齐是因为这样有助于加快计算机的取数速度。编译器默认会让宽度为2的基本数据类型(short等)都位于能被2整除的地址上,让宽度为4的基本数据类型(int等)都位于等被4整除的地址上,以此类推。这样,两个数中间就可能需要加入填充字节。 字节对齐的细节和编译器实现相关,但一般而言,满足三个准则:
- 结构体变量的首地址能够被其最宽基本类型成员的大小所整除;
- 结构体每个成员相对于结构体首地址的偏移量(offset)都是成员大小的整数倍,如有需要编译器会在成员之间加上填充字节(internal adding);
- 结构体的总大小为结构体最宽基本类型成员大小的整数倍,如有需要编译器会在最末一个成员之后加上填充字节(trailing padding)。
上面说到的基本类型是指前面提到的像char、short、int、float、double这样的内置数据类型,这里所说的“数据宽度”就是指其sizeof的大小。由于结构体的成员可以是复合类型,比如另外一个结构体,所以在寻找最宽基本类型成员时,应当包括复合类型成员的子成员,而不是把复合成员看成是一个整体。但在确定复合类型成员的偏移位置时则是将复合类型作为整体看待。比如有:
struct S3
{
char c1;
S1 s;
char c2
};
S1的最宽简单成员的类型为int,S3在考虑最宽简单类型成员时是将S1“打散”看的,所以S3的最宽简单类型为int,这样,通过S3定义的变量,其存储空间首地址需要被4整除,整个sizeof(S3)的值也应该被4整除。
JH, 2013-04-21
参考资料:
- 《深入理解Linux内核》
- 深入分析 Linux 内核链表
- sizeof zz